Nichtprozedural bedeutet »was« statt »wie«. SQL beschreibt, welche Daten abzurufen, zu löschen oder einzufügen sind und nicht, wie das zu geschehen hat.
1. Einführung in SQL
Geschichtlicher Abriß zu Datenbanken
Die Datenbankstruktur entwerfen
Eine produktübergreifende Sprache
Bekannte SQL-Implementierungen
ODBC (Open Database Connectivity)
SQL in der Anwendungsprogrammierung
Geschichtlicher Abriß zu SQL
SQL erblickte Ende der 70er Jahre in einem IBM-Labor in San Jose (Kalifornien) das Licht der Welt. Die Entwicklung war ursprünglich für das IBM-Produkt DB2 vorgesehen (ein relationales Datenbank-Managementsystem, oder RDBMS, das auch heute noch für verschiedene Plattformen und Umgebungen erhältlich ist). SQL steht für Structured Query Language - zu deutsch etwa: strukturierte Abfragesprache. Es handelt sich um eine nichtprozedurale Sprache, im Gegensatz zu den prozeduralen Sprachen oder Sprachen der dritten Generation (3GLs) wie COBOL und C, die zu dieser Zeit entstanden.
|
Nichtprozedural bedeutet »was« statt »wie«. SQL beschreibt, welche Daten abzurufen, zu löschen oder einzufügen sind und nicht, wie das zu geschehen hat. |
Gegenüber einem einfachen DBMS zeichnet sich ein RDBMS durch die mengenorientierte Datenbanksprache aus, die bei den meisten RDBMS in SQL realisiert ist. Mengenorientiert
Die von den Organisationen ANSI (American National Standards Institute) und ISO (International Standards Organization) propagierten SQL-Standards dienen den Datenbankherstellern zum Teil nur als Richtlinien. Alle Datenbankprodukte unterscheiden sich mehr oder weniger vom ANSI-Standard. Darüber hinaus zielen die meisten Systeme mit proprietären Erweiterungen darauf ab, SQL zu einer echten prozeduralen Sprache zu machen. In diesem Buch kommt durchgängig der Standard ANSI-92 zur Anwendung. Die Beispiele arbeiten mit verschiedenen RDBMS, um einen möglichst allgemeinen Überblick über die Datenbanksysteme zu vermitteln. (Die prozeduralen SQL-Erweiterungen PL/SQL und Transact-SQL behandeln wir in den Lektionen 18 bzw. 19.)
Geschichtlicher Abriß zu Datenbanken
Ein paar Hintergrundinformationen zur Entwicklung von Datenbanken und der Datenbanktheorie sollen Ihnen die Arbeitsweise von SQL verständlicher machen. In vielen geschäftlichen und privaten Bereichen greift man auf Informationen in Datenbanken zurück. Ob es sich nun um große Auskunftsdatenbanken für Buchungssysteme bei Fluggesellschaften oder um die Baseball-Kartensammlung eines Kindes handelt - Datenbanken speichern und verteilen die für uns relevanten Daten. Es ist noch nicht allzu lange her, da umfangreiche Datenbanksysteme nur auf Großrechnern laufen konnten.
Diese Maschinen sind mit hohen Kosten für Entwicklung, Anschaffung und Wartung verbunden. Die heutigen leistungsfähigen und billigeren Workstations ermöglichen nun Programme, die Daten schnell und preiswert verwalten und verteilen.
Die 12 goldenen Regeln für relationale Datenbanken
Das bekannteste Modell zur Datenspeicherung ist die relationale Datenbank, die auf den Artikel »A Relational Model of Data for Large Shared Data Banks« von Dr. E. F. Codd aus dem Jahr 1970 zurückgeht. Die Entwicklung von SQL zielt darauf ab, den Konzepten des relationalen Datenbankmodells zu entsprechen. Dr. Codd veröffentlichte 12 Regeln (inklusive Regel 0 eigentlich 13), die eine relationale Datenbank im strengen Sinne definieren:
0. Ein relationales DBMS muß in der Lage sein, Datenbanken vollständig über seine relationalen Fähigkeiten zu verwalten.
1. Darstellung von Informationen: Alle Informationen in einer relationalen Datenbank (einschließlich Namen von Tabellen und Spalten) sind explizit als Werte in Tabellen darzustellen.
2. Zugriff auf Daten: Jeder Wert einer relationalen Datenbank muß durch eine Kombination von Tabellenname, Primärschlüssel und Spaltenname auffindbar sein.
3. Systematische Behandlung von Nullwerten: Das DBMS behandelt Nullwerte durchgängig gleich als unbekannte oder fehlende Daten und unterscheidet diese von Standardwerten.
4. Struktur einer Datenbank: Die Datenbank und ihre Inhalte werden in einem sogenannten Systemkatalog auf derselben logischen Ebene wie die Daten selbst - also in Tabellen - beschrieben. Demzufolge läßt sich der Katalog mit Hilfe der Datenbanksprache abfragen.
5. Abfragesprache: Zu einem relationalen System gehört mindestens eine Abfragesprache mit einem vollständigen Befehlssatz für Datendefinition, Manipulation, Integritätsregeln, Autorisierung und Transaktionen.
6. Aktualisieren von Sichten: Alle Sichten, die theoretisch aktualisiert werden können, lassen sich auch vom System aktualisieren.
7. Abfragen und Bearbeiten ganzer Tabellen: Das DBMS unterstützt nicht nur Abfragen, sondern auch die Operationen für Einfügen, Aktualisieren und Löschen in Form ganzer Tabellen.
8. Physikalische Datenunabhängigkeit: Der logische Zugriff auf die Daten durch Anwendungen und Ad-Hoc-Programme muß unabhängig von den physikalischen Zugriffsmethoden oder den Speicherstrukturen der Daten sein.
9. Logische Datenunabhängigkeit: Änderungen der Tabellenstrukturen dürfen keinen Einfluß auf die Logik der Anwendungen und Ad-Hoc-Programme haben.
10. Unabhängigkeit der Integrität: Integritätsregeln müssen sich in der Datenbanksprache definieren lassen. Die Regeln müssen im Systemkatalog gespeichert werden. Es darf nicht möglich sein, die Regeln zu umgehen.
11. Verteilungsunabhängigkeit: Der logische Zugriff auf die Daten durch Anwendungen und Ad-Hoc-Programme darf sich beim Übergang von einer nicht-verteilten zu einer verteilten Datenbank nicht ändern.
12. Kein Unterlaufen der Abfragesprache: Integritätsregeln, die über die Datenbanksprache definiert sind, dürfen sich nicht mit Hilfe von Low-Level-Sprachen umgehen lassen.
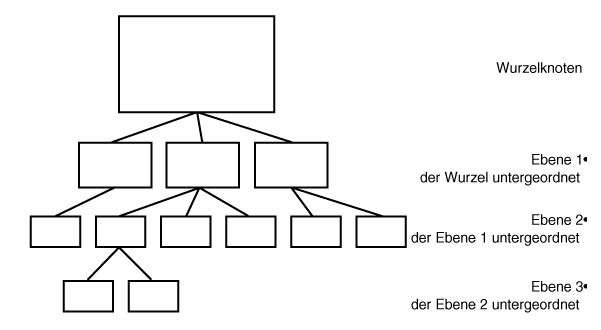
Die meisten Datenbanken sind hierarchisch aufgebaut, wobei der jeweils übergeordnete Knoten mit Zeigern auf untergeordnete Knoten verweist. (Siehe dazu Abbildung 1.1.)
|
Abbildung 1.1: |
Diese Methode hat mehrere Vorteile und viele Nachteile. Positiv ist die Tatsache, daß die physikalische Struktur der Daten auf einem Datenträger nicht von Bedeutung ist. Der Zugriff auf die Daten erfolgt einfach über Zeiger, die auf die nächste Speicherstelle verweisen. Daten lassen sich leicht hinzufügen und löschen. Nachteilig ist, daß man unterschiedliche Informationsgruppen nicht einfach verknüpfen kann, um neue Informationseinheiten zu bilden. Nachdem die Datenbank erstellt wurde, läßt sich das Format der Daten auf dem Datenträger nicht nach Belieben ändern. Bei Änderungen am Format müßte man eine neue Datenbankstruktur erzeugen.
Codd stützt sich in seinem Modell der relationalen Datenbanken auf die mathematischen Konzepte der relationalen Algebra, um Daten in Mengen und miteinander in Beziehung stehende Untermengen aufzuteilen.
Da sich Informationen von Natur aus in unterscheidbaren Mengen gruppieren lassen, baute Dr. Codd sein Datenbanksystem auf diesem Konzept auf. Das relationale Modell gliedert die Daten in Sätze und stellt sie in Form einer Tabellenstruktur dar. Diese Tabellenstruktur besteht aus einzelnen Datenelementen - den sogenannten Spalten oder Feldern. Als Datensatz oder Zeile bezeichnet man einen einzelnen Satz, der eine Gruppe von Feldern zusammenfaßt. Um zum Beispiel eine relationale Datenbank mit Daten von Mitarbeitern zu erzeugen, legt man zunächst eine Tabelle MITARBEITER mit den Elementen Name, Alter und Beruf an. Diese drei Datenelemente bilden die Felder in der Tabelle MITARBEITER, wie sie Tabelle 1.1 zeigt.
Tabelle 1.1: Die Tabelle MITARBEITER
Name |
Alter |
Beruf |
Will Williams |
25 |
Elektroingenieur |
Dave Davidson |
34 |
Museumskurator |
Jan Janis |
42 |
Chef |
Bil Jackson |
19 |
Student |
Don DeMarco |
32 |
Spielprogrammierer |
Becky Boudreaux |
25 |
Model |
Die sechs Zeilen stellen die Datensätze in der Tabelle MITARBEITER dar. Um einen bestimmten Datensatz - zum Beispiel für Dave Davidson - aus dieser Tabelle abzurufen, weist der Benutzer das Datenbank-Managementsystem an, die Datensätze zurückzugeben, in denen das Feld NAME gleich Dave Davidson ist. Soll das DBMS alle Felder des Datensatzes abrufen, erhält der Benutzer den Namen, das Alter und den Beruf des Mitarbeiters zurück. Als Befehlssprache für das Abrufen der Daten aus der Datenbank kommt natürlich SQL zum Einsatz. Die folgende SQL-Anweisung führt zum Beispiel eine derartige Abfrage aus:
SELECT *
FROM MITARBEITER
Die genaue Syntax ist im Moment noch nicht von Bedeutung. Diesem Thema wenden wir uns detaillierter am Anfang des morgigen Tages zu.
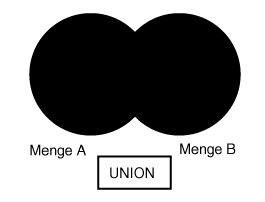
Da sich die verschiedenen Datenelemente aufgrund der naheliegenden Beziehungen (zum Beispiel zwischen Mitarbeiter Name und Mitarbeiter Alter) gruppieren lassen, bietet das relationale Datenbankmodell dem Datenbankentwickler flexible Möglichkeiten, um die Beziehungen zwischen den Datenelementen zu beschreiben. Über die mathematischen Konzepte von Vereinigung (Union) und Schnittmenge (Intersection) können relationale Datenbanken schnell Datenteile aus unterschiedlichen Mengen (Tabellen) abrufen und an den Benutzer oder das Programm als »verknüpfte« Datensammlung zurückgeben. (Siehe dazu Abbildung 1.2.) Durch die Verbundfunktionen lassen sich Informationsmengen in separaten Tabellen speichern und damit Wiederholungen vermeiden.
|
Abbildung 1.2: |
Die in Abbildung 1.3 dargestellte Schnittmenge (INTERSECTION) gibt nur die Daten zurück, die beiden Quellen gemeinsam sind.
|
Abbildung 1.3: |
Das folgende einfache Beispiel zeigt, wie man Daten logisch auf zwei Tabellen aufteilen kann. Tabelle 1.2 heißt VERANTWORTLICHKEITEN und enthält zwei Felder: NAME und PFLICHTEN.
Tabelle 1.2: Die Tabelle VERANTWORTLICHKEITEN
Name |
Pflichten |
Becky Boudreaux |
Lächeln |
Becky Boudreaux |
Gehen |
Bill Jackson |
Studieren |
Bill Jackson |
Job suchen |
Es ist wenig sinnvoll, die Felder ALTER und BERUF der Angestellten in jedem Datensatz zu wiederholen. Die unnötige Duplizierung von Daten verschwendet einerseits Festplattenplatz und erhöht andererseits die Zugriffszeit auf das RDBMS. Wenn man dagegen NAME und PFLICHTEN in einer separaten Tabelle namens VERANTWORTLICHKEITEN ablegt, kann der Benutzer die Tabellen VERANTWORTLICHKEITEN und MITARBEITER über das Feld NAME verknüpfen. Weist man das RDBMS an, alle Felder aus den Tabellen VERANTWORTLICHKEITEN und MITARBEITER mit dem Feld NAME gleich Becky Boudreaux abzurufen, erhält man eine Ergebnismenge wie in Tabelle 1.3 zurück.
Tabelle 1.3: Rückgabewerte aus einer Abfrage, bei der NAME gleich
Becky Boudreaux ist
Name |
Alter |
Beruf |
Pflichten |
Becky Boudreaux |
25 |
Model |
Lächeln |
Becky Boudreaux |
25 |
Model |
Gehen |
Weitere Beispiele für die Vereinigung von Tabellen finden Sie in Lektion 6.
Die Datenbankstruktur entwerfen
Der Entwickler einer Datenbank muß nach Wahl von Hardwareplattform und RDBMS vor allem die Struktur der Tabellen entwerfen. Die Entscheidungen in dieser Entwurfsphase können die Leistung und Programmierung in späteren Stadien des Entwicklungsprozesses beeinflussen. Die Aufteilung der Daten in voneinander verschiedene, eindeutige Sätze nennt man Normalisierung
Moderne Datenbankformate
Die revolutionären Veränderungen in der Computertechnologie beeinflussen die Informationsverarbeitung in den Unternehmen auf der ganzen Welt. Die ehemals in riesigen Sälen mit Plattenspeichern verwalteten Informationen sind nun dezentral verfügbar und auf einfachen Mausklick zu erreichen. Kundenaufträge aus allen Teilen des Erdballs lassen sich nun unmittelbar vor Ort in der Produktionsfirma verarbeiten. Auch wenn die Informationen schon vor längerer Zeit auf firmeneigene Mainframe-Datenbanken übertragen wurden, herrschte in typischen Büroumgebungen weiterhin die Stapelverarbeitung vor. Eine Datenbankabfrage war im Datenverarbeitungszentrum einzureichen - die abgerufenen Daten erhielt man so bald als möglich zurück (auch wenn es manchmal nicht rechtzeitig genug geschah).
Neben dem relationalen Datenbankmodell führten vor allem die Einführung des Personalcomputers und der Aufbau lokaler Netze zu einer rasanten Entwicklung der heutigen - als Client/Server-Datenbanken
Die Personalcomputer mit vergleichsweise preiswerten und vor allem einfach zu bedienenden Anwendungen wie Lotus 1-2-3 und WordPerfect erlaubten den Mitarbeitern (und Benutzern von Heimcomputern), Dokumente zu erstellen und Daten schnell und korrekt zu verwalten. Die Benutzer gewöhnten sich mit der Zeit an die häufigen Systemaktualisierungen, die sich mit der gleichen Geschwindigkeit wie der Preisverfall der immer leistungsfähiger werdenden Systeme vollzogen.
Mit dem Einzug der lokalen Netzwerke (LAN - local area network) in die Büroumgebungen ließen sich die Dateien des jeweiligen Benutzers lokal speichern und standen trotzdem allen Mitarbeitern über die ans Netz angeschlossenen Computer zur Verfügung. Die bisher übliche Kommunikation mit dem Rechenzentrum per Terminal wurde somit durch dezentral arbeitende Datentechnik abgelöst und auf ein höheres Niveau gebracht. Der Apple Macintosh zeigte mit seiner benutzerfreundlichen grafischen Oberfläche, daß Computer nicht nur preiswert und leistungsfähig, sondern auch einfach in der Handhabung sind. Darüber hinaus war der Zugriff von entfernten Standorten möglich, und große Datenmengen ließen sich auf die Daten-Server der Abteilungen auslagern.
In dieser Zeit der schnellen Änderungen und Fortschritte bildete sich ein neuer Systemtyp heraus. Die sogenannte Client/Server-Architektur
Bernard H. Boar definiert die Client/Server-Verarbeitung in »Implementing Client/Server Computing« wie folgt:
Das Client/Server-Modell teilt eine Anwendung zwischen mehreren Prozessoren (Frontend und Backend) auf, wobei die Prozessoren (transparent für den Endbenutzer) zusammenarbeiten, um die Verarbeitung als geschlossene Aufgabe zu realisieren. Ein dem Client/Server-Modell konformes Produkt liefert durch die Verbindung der Prozessoren das Abbild (die Illusion) eines Einzelsystems. Gemeinsam nutzbare Ressourcen nehmen die Position von Abfrage-Clients ein, die auf autorisierte Dienste zugreifen. Die Architektur ist unbegrenzt rekursiv. Server können die Rolle des Clients einnehmen und Dienste von anderen Servern im Netz anfordern und so weiter und so fort.
Diese Art der Anwendungsentwicklung erfordert eine völlig andere Strategie der Programmierung. Die Kommunikation mit dem Benutzer ist über grafische Oberflächen zu realisieren, ob es sich nun um Microsoft Windows, IBM OS/2, Apple Macintosh oder das UNIX-X-Window-System handelt. Per SQL und einer Netzverbindung führt eine Anwendung den Dialog mit einer Datenbank, die sich auf einem entfernten Server befindet. Der enorme Leistungssprung bei Personalcomputern erlaubt die Speicherung kritischer Datenbankinformationen auf einem relativ preisgünstigen eigenständigen Server. Außerdem läßt sich dieser Server später ersetzen, wobei nur geringe oder gar keine Änderungen der Client-Anwendungen erforderlich sind.
Eine produktübergreifende Sprache
Die in diesem Buch eingeführten Grundkonzepte kann man auf viele Umgebungen übertragen - beispielsweise Microsoft Access, das als Einbenutzer-Windows-Anwendung läuft, oder SQL Server mit 100 angeschlossenen Benutzern. Einer der größten Vorteile von SQL besteht darin, daß es sich um eine echte plattformunabhängige und produktübergreifende Sprache handelt. Da es außerdem eine höhere Sprache der vierten Generation (4GL) ist, lassen sich komplexe Funktionen mit weniger Codezeilen formulieren.
Frühe Implementierungen
Die Firma Oracle veröffentlichte das erste kommerzielle RDBMS, das mit SQL arbeitete. Obwohl die ursprüngliche Version für VAX/VMS-Systeme entwickelt wurde, war Oracle einer der ersten Anbieter einer DOS-Version seines RDBMS. (Oracle ist derzeit auf mehr als 70 Plattformen verfügbar.) In der Mitte der 80er Jahre veröffentlichte Sybase sein RDBMS - SQL Server. Mit Client-Bibliotheken für Datenbankzugriff, Unterstützung für gespeicherte Prozeduren (siehe Tag 14) und der Zusammenarbeit zwischen verschiedenartigen Netzwerken wurde SQL Server insbesondere in Client/Server-Umgebungen zu einem erfolgreichen Produkt. Beide Produkte zeichnen sich durch Skalierbarkeit über Plattformen hinweg aus. Für Oracle auf dem PC in der Sprache C (kombiniert mit SQL) geschriebener Code ist nahezu identisch mit seinem Pendant für eine Oracle-Datenbank, die auf einem VAX-System läuft.
SQL und Client/Server-Anwendungsentwicklung
Der rote Faden, der sich durch die gesamte Client/Server-Anwendungsentwicklung zieht, ist die Arbeit mit SQL und relationalen Datenbanken. Außerdem ist eine Einbenutzer-Büroanwendung durch den Einsatz dieser Datenbanktechnologie für zukünftiges Wachstum gerüstet.
Ein Überblick über SQL
SQL ist die De-facto-Standardsprache, mit der sich Daten aus relationalen Datenbanken abrufen und dort manipulieren lassen. Mit SQL kann der Programmierer oder Datenbankadministrator folgende Aufgaben ausführen:
|
Die Bezeichnung SQL sollte man nicht auf die Goldwaage legen. Während das S für Structured (Strukturiert) und L für Language (Sprache) ohne weiteres klar sind, stellt das Q für Query (Abfrage) einen Kompromiß dar. Man könnte annehmen, daß sich SQL ausschließlich auf die Abfrage von Datenbanken bezieht. Es lassen sich aber nicht nur Abfragen ausführen, sondern auch Tabellen erzeugen, Daten hinzufügen, Daten löschen, Daten zusammenführen, Aktionen aufgrund von Änderungen an der Datenbank auslösen und Abfragen innerhalb eines Programms oder der Datenbank speichern. Query steht also stellvertretend für eine ganze Reihe von Funktionen. |
Die am häufigsten eingesetzte SQL-Anweisung ist die SELECT-Anweisung (siehe Tag 2). Diese Anweisung ruft Daten aus der Datenbank ab und gibt sie an den Benutzer zurück. Das Beispiel mit der Tabelle MITARBEITER zeigt den typischen Einsatz dieser Anweisung. Neben SELECT bietet SQL Anweisungen für das Erstellen neuer Datenbanken, Tabellen, Felder und Indizes sowie das Einfügen und Löschen von Datensätzen.
ANSI SQL empfiehlt auch eine Kerngruppe von Funktionen der Datenmanipulation. Viele Datenbanksysteme bieten darüber hinaus Werkzeuge für die Sicherstellung der Datenintegrität und die Durchsetzung der Sicherheit (siehe dazu Tag 11). Damit kann der Programmierer die Ausführung einer Gruppe von Befehlen stoppen, wenn eine bestimmte Bedingung auftritt.
Bekannte SQL-Implementierungen
Dieser Abschnitt nennt einige der bekannteren Implementierungen von SQL, die jeweils eigene Stärken und Schwächen aufweisen. Während manche SQL-Implementierungen für den PC und eine einfache Benutzerbedienung ausgelegt sind, wurden andere speziell für sehr große Datenbanken (VLDB - Very Large Databases) konzipiert. Die folgenden Abschnitte gehen auf ausgewählte Schlüsselmerkmale bestimmter Implementierungen ein.
|
Das Buch ist nicht nur als SQL-Referenz konzipiert, sondern zeigt auch viele praktische Beispiele für die Softwareentwicklung. SQL läßt sich vor allem sinnvoll einsetzen, wenn man Probleme der Praxis innerhalb des eigenen Codes lösen kann. |
Microsoft Access
Microsoft Access kommt in einigen Beispielen als PC-basiertes DBMS zum Einsatz. Die SQL-Anweisungen lassen sich manuell eingeben oder mit den Werkzeugen der Benutzeroberfläche erstellen.
Personal Oracle8
Für den Bereich der größeren Firmendatenbanken demonstrieren wir anhand von Personal Oracle8 die Arbeit mit SQL auf der Befehlszeile und Techniken der Datenbankverwaltung. (Diese Techniken sind wichtig, da die Tage der eigenständigen Maschine dem Ende zu gehen, genau wie die Tage, da man mit nur einer Datenbank oder einem Betriebssystem auskam.) SQL*Plus von Oracle dient dabei als Werkzeug, mit dem wir einfache und eigenständige SQL-Anweisungen eingeben. Es zeigt die Daten für den Benutzer auf dem Bildschirm an oder realisiert die jeweilige Aktion in der Datenbank.
Die meisten Beispiele richten sich an den Einsteiger oder erstmaligen Benutzer von SQL. Wir beginnen mit den einfachsten SQL-Anweisungen und arbeiten uns bis zur Transaktionsverwaltung und der Programmierung gespeicherter Prozeduren vor. Im Lieferumfang des Oracle-RDBMS ist ein kompletter Satz von Entwicklungswerkzeugen enthalten. Dazu gehören eine C++- eine und Visual-Basic-Sprachbibliothek (Oracle Objects for OLE), die eine Anwendung mit einer Personal-Oracle-Datenbank verknüpfen können. Außerdem bietet Oracle grafische Werkzeuge für die Verwaltung von Datenbanken, Benutzern und Objekten sowie das Dienstprogramm SQL*Loader, mit dem sich Daten von und zu Oracle importieren und exportieren lassen.
|
Personal Oracle8 ist eine abgespeckte Version des vollständigen Server-Produkts Oracle8. Personal Oracle8 erlaubt nur Einzelbenutzer-Verbindungen (wie es bereits der Name impliziert). Allerdings ist die im Produkt verwendete SQL-Syntax identisch mit der der größeren und teureren Versionen von Oracle. Außerdem haben die in Personal Oracle8 verwendeten Werkzeuge vieles mit dem Produkt Oracle8 gemeinsam. |
Die Wahl fiel aufsmehreren Gründen auf das RDBMS Personal Oracle8:
Abbildung 1.4 zeigt SQL*Plus aus dieser Werkzeug-Suite.
|
Abbildung 1.4: |
|
Beachten Sie bitte, daß sich fast alle im Buch vorgestellten SQL-Beispiele auf andere Datenbanksysteme übertragen lassen. Sollte sich die Syntax grundsätzlich von Produkten anderer Anbieter unterscheiden, weisen wir mit entsprechenden Beispielen auf diese Unterschiede hin. |
Microsoft Query
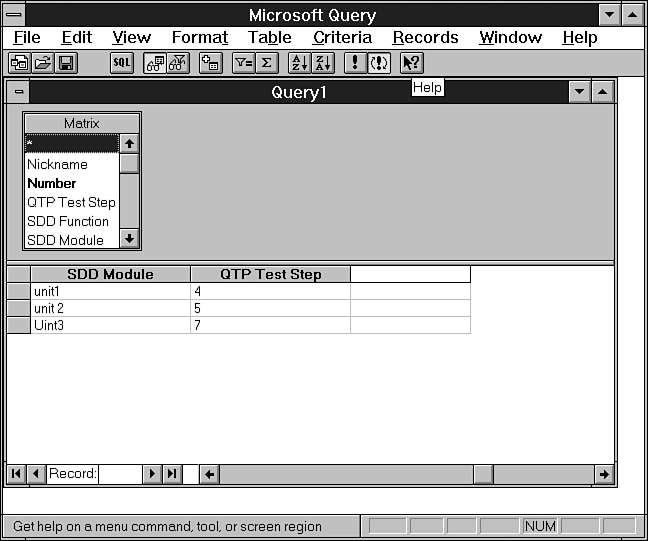
Das Programm Microsoft Query (siehe Abbildung 1.5) gehört zum Lieferumfang verschiedener Entwicklungswerkzeuge von Microsoft, beispielsweise Visual C++ und Visual Basic. Die Kommunikation mit den zugrundeliegenden Datenbanken erfolgt nach dem ODBC-Standard. Microsoft Query übergibt SQL-Anweisungen an einen Treiber, der die Anweisungen verarbeitet und sie dann an ein Datenbanksystem weiterreicht.
|
Abbildung 1.5: |
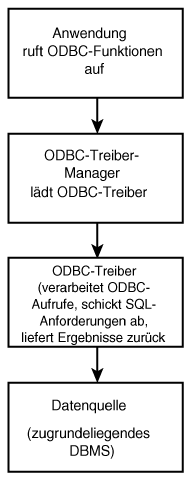
ODBC (Open Database Connectivity)
ODBC steht für Open Database Connectivity und definiert eine Schnittstelle für offenen und herstellerunabhängigen Datenbankzugriff. Anwendungen können damit per SQL als Standardsprache auf Daten zugreifen. Die Kommunikation mit der Datenbank erfolgt über einen Bibliothekstreiber - in der gleichen Art und Weise wie Windows mit einem Drucker über den jeweiligen Druckertreiber kommuniziert. Je nach der eingesetzten Datenbank kann ein Netzwerktreiber erforderlich sein, um die Verbindung zu einer entfernten Datenbank herzustellen. Die Architektur von ODBC zeigt Abbildung 1.6.
|
Abbildung 1.6: |
Die Besonderheit von ODBC (gegenüber den Bibliotheken von Oracle oder Sybase) besteht darin, daß keine Funktion spezifisch zu einem Datenbankanbieter ist. Beispielsweise kann man mit ein und demselben Code - eventuell mit geringen Modifikationen - Abfragen bezüglich einer Microsoft Access-Tabelle oder einer Informix-Datenbank ausführen. Außerdem sei darauf hingewiesen, daß die meisten Anbieter proprietäre Erweiterungen am SQL-Standard vornehmen, etwa bei Transact-SQL von Microsoft und Sybase oder PL/SQL von Oracle.
Man sollte sich immer mit der Dokumentation beschäftigen, bevor man an die Arbeit mit einer neuen Datenquelle geht. ODBC hat sich zu einem Standard herausgebildet, der in viele Produkte eingeflossen ist. Dazu gehören Visual Basic, Visual C++, FoxPro, Borland Delphi und PowerBuilder. Der Anwendungsentwickler muß entscheiden, ob die Datenbankunabhängigkeit bei Programmen gemäß ODBC-Standard oder höhere Geschwindigkeiten bei Einsatz einer datenbankspezifischen Funktionsbibliothek im Vordergrund stehen. ODBC ist zwar portabler, aber gegenüber den Bibliotheken von Oracle8 oder Sybase auch langsamer.
SQL in der Anwendungsprogrammierung
SQL wurde im Jahre 1986 als ANSI-Standard formuliert. Der ANSI-1989-Standard (oder SQL-89) definiert innerhalb eines Anwendungsprogramms drei Typen der Kommunikation mit SQL:
Vor der Einführung von dynamischem SQL setzte man vorrangig eingebettetes SQL in Anwendungsprogrammen ein. Eingebettetes SQL - das man auch weiterhin verwendet - arbeitet mit statischem
Der Standard ANSI 1992 (SQL-92) erweiterte die Sprache und setzte sich als internationaler Standard durch. Dieser Standard definiert drei Ebenen des Sprachumfangs: Entry, Intermediate und Full. Zu den neu eingeführten Merkmalen gehören:
Dieses Buch behandelt nicht nur die genannten Erweiterungen, sondern geht auch auf bestimmte proprietäre Erweiterungen der einzelnen RDBMS-Anbieter ein. Mit dynamischem SQL lassen sich SQL-Anweisungen zur Laufzeit vorbereiten. Dynamisches SQL schneidet hinsichtlich der Leistung zwar schlechter ab als eingebettetes SQL, bietet aber dem Anwendungsentwickler (und Benutzer) ein größeres Maß an Flexibilität. Schnittstellen auf Aufrufebene wie ODBC oder die DB-Bibliothek von Sybase sind Beispiele für dynamisches SQL.
Schnittstellen auf Aufrufebene dürften dem Anwendungsprogrammierer nicht neu sein. Wenn man mit ODBC arbeitet, füllt man zum Beispiel einfach eine Variable mit der SQL-Anweisung und ruft eine Funktion auf, um die SQL-Anweisung an die Datenbank zu schicken. Fehler oder Ergebnisse erhält man über Aufrufe anderer Funktionen, die speziell für diese Zwecke vorgesehen sind. Ergebnisse werden über das sogenannte Binden von Variablen
Zusammenfassung
Der erste Tag ist auf die Geschichte und Struktur von SQL eingegangen. Da SQL und relationale Datenbanken eng miteinander verknüpft sind, behandelt Tag 1 auch (wenn auch kurz) die Geschichte und Funktion von relationalen Datenbanken. Der morgige Tag ist der wichtigsten Komponente von SQL gewidmet: der Abfrage.
Fragen und Antworten
Frage:
Warum sollte ich mich mit SQL befassen?
Antwort:
Wenn Sie nicht gerade mit einem großen Datenbanksystem gearbeitet haben, sind Sie wahrscheinlich kaum mit SQL in Berührung gekommen. Durch die Einführung der Client/Server-Entwicklungswerkzeuge (wie etwa Visual Basic, Visual C++, ODBC, Borlands Delphi und PowerBuilder von Powersoft) und die Übertragung großer Datenbanken (Oracle und Sybase) auf die PC-Plattform erfordern die meisten der heute entwickelten Büroanwendungen ein fundiertes Wissen zu SQL.
Frage:
Warum muß ich mich mit der Theorie der relationalen Datenbanken beschäftigen, wenn ich SQL einsetzen möchte?
Antwort:
SQL wurde für die Bedienung von relationalen Datenbanken entwickelt. Ohne minimale Kenntnisse der Theorie relationaler Datenbanken können Sie SQL - außer in den trivialsten Fällen - nicht effektiv nutzen.
Frage:
Mit den neueren grafisch orientierten Werkzeugen läßt sich SQL auf Mausklick hin erstellen. Warum sollte ich meine Zeit mit dem manuellen Schreiben von SQL verschwenden?
Antwort:
Zweifellos haben sowohl grafische Benutzeroberflächen als auch das manuelle Verfassen von SQL-Anweisungen ihren Platz. Manuell geschriebenes SQL ist im allgemeinen effizienter als SQL, das per grafischer Benutzeroberfläche erstellt wird. Außerdem läßt sich eine mit grafischen Hilfsmitteln erzeugte SQL-Anweisung nicht so einfach lesen wie eine manuell verfaßte. Schließlich kann man mit dem Wissen um die Abläufe hinter den Kulissen den größten Nutzen aus den Werkzeugen grafischer Benutzeroberflächen herausholen.
Frage:
Müßte ich nicht SQL aufgrund der Standardisierung für die Programmierung jeder Datenbank einsetzen können?
Antwort:
Nein. Man kann mit SQL nur RDBMS-Datenbanken programmieren, die SQL unterstützen. Dazu gehören zum Beispiel Microsoft Access, Oracle, Sybase und Informix. Auch wenn sich die Implementierungen der einzelnen Hersteller etwas unterscheiden, sollte man SQL mit geringfügigen Anpassungen einsetzen können.
Workshop
Die Kontrollfragen des Workshops sollen Ihr Verständnis für das behandelte Material vertiefen. Außerdem haben Sie in den hier gebotenen Übungen Gelegenheit, etwas praktische Erfahrungen zu sammeln. Versuchen Sie, die Kontrollfragen zu beantworten und die Übungen durchzuarbeiten, bevor Sie sich die Lösungen im Anhang F ansehen.
Kontrollfragen
1. Weshalb spricht man bei SQL von einer nichtprozeduralen Sprache?
2. Wie kann man erkennen, ob eine Datenbank tatsächlich echt relational ist?
3. Welche Aufgaben lassen sich mit SQL realisieren?
4. Wie bezeichnet man den Prozeß, der Daten in voneinander verschiedene, eindeutige Sätze aufteilt?
Übung
Finden Sie heraus, ob die Datenbank, mit der Sie zu Hause oder im Büro arbeiten, echt relational ist.